

最近、AIアシスタントやチャットボットが私たちの日常に急速に浸透してきています。
しかし、「なんだか話が噛み合わないな」「前にも同じことを伝えたはずなのに…」と感じた経験はありませんか?実は、その原因の多くはAIが「文脈(コンテキスト)」を正しく理解できていないことにあります。今回は、そんなAIの課題を解決し、AIを真に賢くするための重要な技術「コンテキストエンジニアリング」について、私の経験も交えながら、できるだけ分かりやすくお話ししたいと思います。
1. コンテキストエンジニアリングとは何か?
まず、「コンテキストエンジニアリング」という言葉自体、あまり聞き馴染みがないかもしれません。簡単に言うと、「AIがその時々で必要とする情報を、最適な形で与えるための設計技術」のことです。
GPT-4のような強力な大規模言語モデル(LLM)も、実はデフォルトでは記憶を持っていません。まるで、数秒前のことも忘れてしまう鳥のようです。私たちがプロンプト(指示文)として与えた情報だけが、その瞬間のAIにとっての全世界なのです。そのため、ユーザーの入力情報にどのような「文脈」を添えてあげるかが、AIの性能を決定づける上で非常に重要になります。
プロンプトエンジニアリングが「AIへの的確な指示出し」の技術だとすれば、コンテキストエンジニアリングは、その指示を取り巻く「情報環境全体のデザイン」と言えるでしょう。会話の履歴、ユーザーの好み、過去の成功・失敗体験など、あらゆる情報を整理し、AIが最高のパフォーマンスを発揮できるお膳立てをしてあげるのが、この技術の役割です。
2. なぜコンテキストエンジニアリングが重要なのか?

では、なぜ今、このコンテキストエンジニアリングがこれほどまでに重要視されているのでしょうか。その理由は大きく分けて5つあります。
2.1. AIの「記憶」を創り出す
先ほども述べたように、LLMには長期的な記憶がありません。限られたテキストウィンドウ(一度に処理できる情報量)の中でしか思考できないため、会話が長くなると、誰と話しているのか、どんな話題だったのかを忘れてしまいます。これでは、まるで初対面の人と何度も話しているようなもので、深い対話は望めません。
コンテキストエンジニアリングは、過去のやり取りを要約したり、重要な情報だけを抽出して保持したりすることで、AIに擬似的な「記憶」を与えます。これにより、AIは会話の流れを維持し、一貫性のある応答を返すことができるようになるのです。
2.2. 「ハルシネーション(幻覚)」を防ぐ
AIが自信満々に全くの嘘をつく現象、いわゆる「ハルシネーション」に遭遇したことがある方も多いでしょう。これは、AIが必要な情報を与えられず、推測で補おうとすることで発生します。
優れたコンテキストエンジニアリングは、AIを「事実」にしっかりと結びつけます。例えば、法律相談AIを開発する場合、対象となる国の法律や判例といった正確な情報をコンテキストとして与えることで、AIが勝手に法律を作り出してしまうといった危険な事態を防ぐことができます。
2.3. 複雑なタスクを遂行する
複数のステップにまたがる複雑なタスクをAIに任せたい場合、各ステップ間で情報を引き継ぐ仕組みが不可欠です。例えば、「A社の最新の決算情報を調べて、その内容を要約し、プレゼン資料の構成案を作成して」といった指示を考えてみましょう。
この場合、「決算情報を調べる」というステップで得られた情報を、次の「要約する」ステップに正しく渡さなければなりません。コンテキストエンジニアリングは、このようなステップ間の情報の受け渡しを設計し、AIが長期的な計画に沿ってタスクを遂行できるようにします。
2.4. 「あなただけ」のAIにパーソナライズする
私たちがAIに「もっと人間らしくなってほしい」と願うとき、その本質は「私のことを覚えて、私に合わせてほしい」という想いにあるのではないでしょうか。このパーソナライゼーションの鍵を握るのも、コンテキストです。
ユーザーがメールよりも音声メモを好む、箇条書きでの回答を求める、といった個人の特性をコンテキストとして反映させることで、AIはまるで気の利く秘書のように、ユーザー一人ひとりに最適化された対応を提供できるようになります。私の開発経験の中でも、ユーザーの過去のフィードバック(特に、どの回答に満足し、どの回答に不満だったか)をコンテキストに含めるだけで、ユーザー満足度が劇的に向上したケースがありました。
2.5. コストとパフォーマンスを最適化する
実用的な観点から見ても、コンテキストエンジニアリングは非常に重要です。LLMの利用は、処理する情報量(トークン数)に応じてコストがかかります。また、コンテキストウィンドウには上限があるため、無関係な情報で溢れかえっていると、本当に必要な情報が失われてしまいます。
賢いコンテキストエンジニアリングは、入力する情報を最適化する技術でもあります。重要な情報を優先し、必要に応じて要約し、不要な情報を削ぎ落とす。これは単に明確さを高めるだけでなく、AIの応答速度、コスト、そして出力の質そのものを向上させることにつながるのです。
3. コンテキストエンジニアリングの具体的な手法
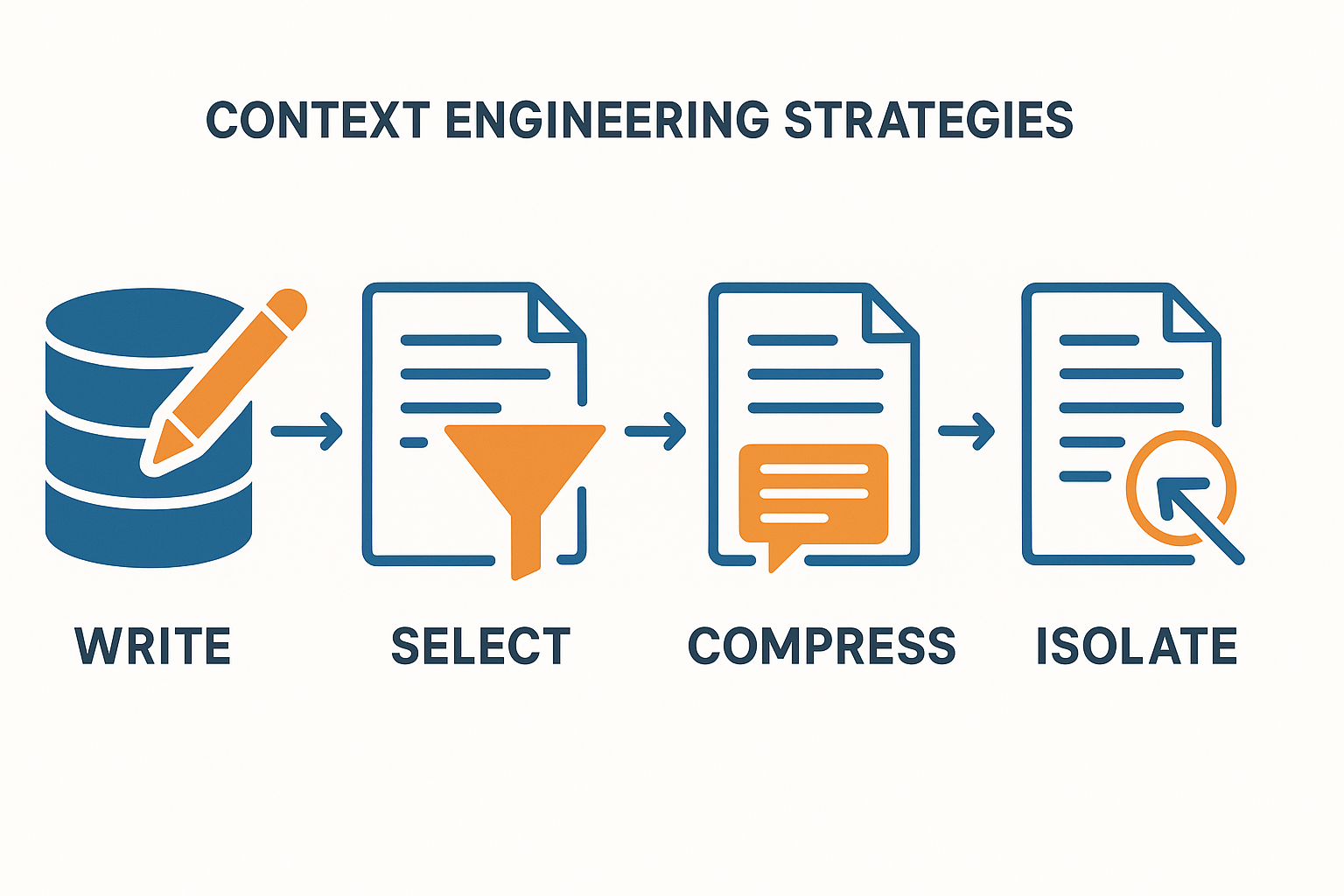
では、具体的にどのようにコンテキストを操作するのでしょうか。LangChainなどのフレームワークでは、いくつかの戦略が提唱されています。ここでは、その中でも代表的な4つのアプローチをご紹介します。
Write(書き込み)
会話の履歴やユーザー情報など、将来必要になりそうな情報を「メモリ」に保存します。例えば、ユーザーが「私は猫アレルギーです」と伝えた情報を、ユーザープロファイルに記録しておく。
Select(選択)
保存された情報の中から、現在のタスクに最も関連性の高い情報を選び出してLLMに与えます。例えば、レストランを予約するタスクでは、ユーザープロファイルから「猫アレルギー」の情報を取り出し、「猫カフェは避ける」という判断に利用する。
Compress(圧縮)長い会話の履歴や大量の情報を、要点をまとめた短いテキストに圧縮します。例えば、100ターンに及ぶ顧客とのチャット履歴を、「顧客は製品Aの納期遅延に不満を持っている」という一文に要約する。
Isolate(隔離)タスクに不要な情報や、AIに偏見を与える可能性のある情報を意図的に隠し、クリーンな環境で思考させます。例えば、コード生成タスクにおいて、過去の自然言語での会話履歴を一旦隔離し、プログラミングに関する情報のみを与えることで、ノイズを減らす。
私自身の経験から言うと、特に「Compress(圧縮)」は非常に強力です。あるプロジェクトで、AIエージェントが長時間の対話で混乱し、同じ質問を繰り返すという問題に直面しました。そこで、数ターンごとに会話の要約を生成し、それを「短期記憶」としてコンテキストに含めるようにしたところ、エージェントのパフォーマンスが劇的に安定しました。これは、人間が長い会議の後に議事録を作成するのに似ていますね。
4. 実装における課題と今後の展望
コンテキストエンジニアリングは強力な技術ですが、万能ではありません。どの情報を、どのタイミングで、どのくらいの粒度で与えるべきか、という判断は非常に難しく、プロジェクトの要件によって最適解は異なります。関連性の低い情報を大量に与えてしまい、かえってAIを混乱させてしまったという失敗も、私自身、数多く経験してきました。
しかし、この分野は急速に進化しています。LangGraphのようなステートフル(状態を持つ)なAIエージェントを構築するためのフレームワークが登場し、より洗練されたコンテキスト管理が可能になってきています。将来的には、AI自身がコンテキストを自律的に管理し、人間が細かく設計しなくても、状況に応じて最適な情報環境を構築できるようになるかもしれません。
まとめ
強力なLLMを手に入れるだけでは、本当に賢いAIエージェントを作ることはできません。その性能を最大限に引き出す鍵は、AIが思考するための「情報環境」をいかに巧みにデザインするか、すなわち「コンテキストエンジニアリング」にかかっています。
それは、AIの記憶を創り、幻覚を防ぎ、複雑なタスクを可能にし、一人ひとりに寄り添うことを実現する、まさにAIの「背骨」となる技術です。まだ発展途上の分野ではありますが、AIと人間がより良い関係を築いていく上で、コンテキストエンジニアリングが中心的な役割を果たしていくことは間違いないでしょう。
あわせて読みたい






